|
||||||
|
||||||
DOCUMENTS
elab.immagini
galileo
realtà virtuale
vrml
biomeccanica
esapodi
formula1
intelligenza
Papers
meccanica
sistemi
robotica
L'obbiettivo era quello di costruire una rete che formasse propri significati, per fare ciò, abbiamo applicato i concetti generali, esposti alla fine del secondo capitolo.
Tale rete deve, quindi, decidere le proprie azioni in base alla situazione ambientale, alla propria situazione interna (ma per semplificare si abbiamo provato una rete con un solo scopo e quindi la sua situazione interna rimaneva costante) ed agli effetti delle azioni passate.
Quest'ultimo obbiettivo implicava la necessità di implementare una sorta di rinforzo. Gran parte degli sforzi li abbiamo così rivolti al tentativo di organizzare una rete capace di autovalutare il risultato delle proprie azioni e rinforzare le azioni che davano un risultato positivo.
La valutazione doveva essere di due tipi:
- una implicita, fisica, data dalla risposta che automaticamente la rete produceva in risposta ad una data stimolazione;
- una emotiva, costituita da un'altra rete che valutava in termini di positivo e negativo quello che sarebbe accaduto in seguito alla risposta che aveva prodotto la prima rete (che chiameremo motoria). Questa valutazione non era fatta analizzando sistematicamente gli effetti dei movimenti che si accingeva a compiere, ma basandosi esclusivamente sull'esperienza precedente. Certamente è un'esagerazione definirla emotiva, essa non riproduce tutta la complessità del fenomeno emotivo, non cambia il modo di lavorare della rete motoria, non altera lo stato generale dell'automa, ma si limita a rifiutare azioni giudicate ad effetto negativo. Comunque possiamo considerarla la forma più semplice che riusciamo ad immaginare di valutazione emotiva, capace di distinguere solo tra una situazione che è appetibile ed una che è pericolosa.
Abbiamo quindi tenuto costante (con piccole modifiche) la strutturazione generale dell'automa, che prevedeva questa dipendenza delle azioni dalla situazione ed abbiamo provato diverse leggi di apprendimento, cercando di fornirlo di un rinforzo delle azioni che, in una certa situazione, erano valutate positivamente.
Inizialmente abbiamo tentato con l'ART2 (Grossberg, 1987) per categorizzare le situazioni, ma esso categorizza astraendo le caratteristiche più grossolane e livellando le differenze minori, ciò non garantisce che vengano raggruppate insieme le situazioni che richiedono le stesse risposte. Anzi piccole differenze nelle situazioni possono richiedere grandi differenze nelle risposte e viceversa.
Si è preferito allora associare situazioni e risposte con una legge di associazione lineare. In entrambi i casi (come nei successivi) il rinforzo era costituito dalla modifica dei coefficienti delle connessioni (secondo le rispettive leggi) solo nei casi in cui le azioni si rivelano positive. Questo tentativo ha dato risultati ancora più insoddisfacenti, non spostandosi in maniera rilevante da un comportamento casuale.
Abbiamo provato, allora a sostituire alla legge di associazione lineare la back-propagation ed a implementare un minimo di indebolimento delle azioni negative. Quest'indebolimento è stato ottenuto, in un primo tempo calcolando normalmente con la backpropagation i differenziali delle connessioni, ma applicandoli con il segno inverso. Successivamente abbiamo provato cambiando il segno della connessione tra il neurone dello strato sensorio e dello strato associativo più attivi in occasione dell'azione valutata negativamente. Ambedue questi accorgimenti hanno dato risultati insoddisfacenti (anche se non sono stati valutati approfonditamente) e sono stati progressivamente abbandonati, ma l'architettura generale dell'automa è risultata abbastanza efficace, dimostrando di apprendere dall'ambiente così come ci proponevamo.
Abbiamo provato un numero difficilmente precisabile di versioni diverse, perché molte erano tentativi che si rivelavano subito inefficienti, altre erano delle piccole variazioni che non si possono considerare versioni diverse. In più anche la stessa versione non è detto che apprenda allo stesso modo in due sessioni di apprendimento diverse.
Non ci dilungheremo su molti cambiamenti relativi alle prime versioni, ma faremo solo alcuni accenni ad essi ed inizieremo ad illustrare più approfonditamente le ultime versioni.
Molti cambiamenti sono ispirati a considerazioni tratte dalla letteratura sugli automi, indipendentemente dal sistema di apprendimento utilizzato, la cui importanza non è fondamentale. Altri sono basati su considerazioni generali di carattere psicologico o etologico.
Gli automi basati sugli algoritmi genetici, che si evolvono una generazione dopo l'altra modificando la propria struttura (ma ve ne sono anche sempre più che evolvono modificando il valore delle connessioni) possono essere considerati più propriamente simulazioni dell'evoluzione e quelli che apprendono utilizzando altri meccanismi per modificare le proprie connessioni, come simulazioni di apprendimento vero e proprio. Il nostro tentativo comprende un pò entrambi i meccanismi, in quanto queste diverse versioni possono essere considerati una sorta di evoluzione "guidata", un pò "lamarkiana".
L'automa è formato da 5 elementi: un corpo di 3 elementi allineati orizzontalmente ed un braccio di due elementi con la possibilità di ruotare il primo intorno all'elemento allineato di sinistra ed il secondo intorno al primo elemento ruotante.

FIGURA 1. Struttura dell'automa.
E' inserito in un ambiente discreto di 9 per 9 caselle in cui i margini sono collegati così che uscire a destra porta a rientrare a sinistra ed uscire sopra a rientrare sotto (superficie toroidale).
Si può muovere in questo ambiente di un passo per volta, in ogni direzione, potendo inoltre combinare i suoi movimenti con quelli dei due elementi del braccio ruotante. Quindi in ogni istante può decidere tra 9*3*3 = 81 (le 8 direzioni diverse in cui può muoversi, più la possibilità di non muoversi, per le due direzioni di rotazione più la non rotazione per ognuno dei due segmenti) diverse combinazioni di movimenti.
L'ambiente contiene elementi verso i quali muoversi (cibo) e da evitare (mine). In ogni momento le 81 caselle sono occupate da 15 elementi positivi (cibo) e 15 negativi (mine), oltre all'automa che occupa 5 caselle, in questo modo rimangono 46 caselle vuote.
Illustreremo gli altri aspetti dell'automa specificando le varie versioni, in quanto sono state fatte diverse modifiche, provando delle varianti suggerite dalla letteratura o da riflessioni generali di carattere psicologico.
Fino qui è evidente come si volesse semplicemente realizzare un agente situato che fosse in grado di mostrare un comportamento un pò più complesso, del semplice inseguire una preda.
D'altra parte non è consigliabile, per ora, tentare di realizzare automi troppo complessi, date le limitazioni tecniche. Infatti, dovendo simulare il comportamento di una rete su un sistema in realtà di tipo digitale, si ha una crescita esponenziale dei tempi di calcolo con l'aumentare del numero dei neuroni. Così abbiamo avuto il grosso limite di contenere il numero dei neuroni e quindi le possibilità dell'automa.
Comunque il nostro proposito era semplicemente quello di mettere alla prova l'ipotesi che il significato sorge spontaneamente, nel modo indicato in precedenza, in determinate circostanze.
Il nostro automa, pur in una situazione semplificata, deve affrontare un ambiente continuamente mutevole che cambia sia in conseguenza delle sue azioni che indipendentemente da esse. Le sue possibilità di movimento sono relativamente complesse, potendo muovere non solo se stesso nelle otto direzioni classiche di una griglia, ma avendo anche il controllo di un braccio mobile.
Versioni precedenti a quella finale e funzionamento
RSIB7D e cenni alle versioni precedenti
Questa versione dell'automa ha la possibilità di percepire tutte le caselle attigue al secondo elemento ruotante ed agli elementi orizzontali per un totale di 20 caselle "percepite". Il suo sistema nervoso è costituito di due reti a tre strati di neuroni, una determina i suoi movimenti (rete motoria o principale) ed una prevede gli effetti in termini di positività o negatività della situazione che ne seguirebbe (deputata quindi a valutare la situazione dandole una significato emotivo e definita rete previsione).
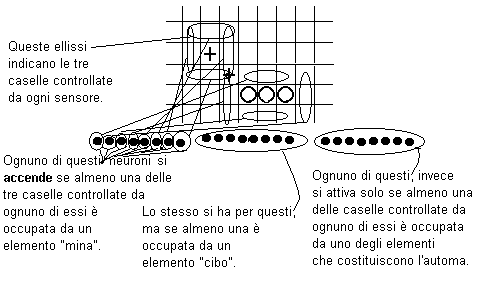
FIGURA 2. Primo strato di neuroni della rete principale.
Il primo strato è costituito, nella prima rete, di 24 neuroni e nella seconda di 28 il secondo di 20 neuroni in entrambe le reti ed il terzo di 8 nella prima e 10 nella seconda. Come mostrato dalla figura i 24 recettori sono di tre tipi diversi: 8 percepiscono le mine, 8 il cibo ed 8 se stesso.
Nelle prime versioni il primo strato era costituito da 60 neuroni, infatti ognuno era sensibile allo stato di una casella. Questo sistema però è da una parte scomodo per la nostra necessità di limitare, in queste simulazioni, il numero dei neuroni; e dall'altra perché non corrisponde ai principi della percezione naturale. Il nostro automa dovrebbe simulare il comportamento di un organismo fornito di un solo sistema percettivo di tipo tattile. Nella realtà i recettori tattili si dividono in varie categorie che percepiscono ognuno sensazioni di tipo diverso e ciò è riprodotto adeguatamente. Perché ci sia la percezione di una certa sensazione tattile e quindi di un determinato oggetto, però, ci dovrebbe essere la partecipazione di più recettori. Nel nostro caso, invece, avevamo inizialmente una corrispondenza di uno a uno, che da un lato semplifica troppo la situazione e dall'altra, probabilmente, ostacola l'emergenza di percezioni globali, complesse. Per ottenere comunque qualcosa del genere, pur in un ambiente discreto, abbiamo fatto in modo che ogni sensore percepisse lo stato di più caselle e che quindi, la presenza di un dato oggetto in una determinata casella, dovesse essere ricavato con la partecipazione dello stato di più recettori.
Il primo strato della rete "previsione", è costituito da 24 neuroni aventi le stesse funzioni di quelli del primo strato della rete principale (vedi FIGURA 2.), più 4 neuroni che codificano il movimento che l'automa si accinge a fare.
Ogni neurone di ciascuno strato è collegato con tutti i neuroni dello strato superiore. Il terzo strato della rete principale determina i movimenti. I primi due "decidono" la direzione (destra/sinistra): se il primo ha un valore maggiore va a sinistra se ha un valore maggiore il secondo a destra se hanno una differenza minore di 0,33 non si muove in nessuna delle due direzioni. Il movimento verso alto/basso viene deciso dal settimo ed ottavo neurone (il settimo verso il basso, l'ottavo verso l'alto). Il terzo ed il quarto determinano il verso di rotazione del primo elemento del braccio: se ha un valore maggiore il terzo si ha una rotazione antioraria, se è maggiore il quarto la rotazione sarà in senso orario, se hanno una differenza minore di 0,33 non c'è rotazione. Lo stesso avviene per il quinto e sesto nei riguardi della seconda porzione di braccio.
In questo modo l'uscita motoria è costituita da un vettore di otto elementi dato dai valori assunti dallo strato di uscita della rete principale, ma il movimento è codificato da un vettore di quattro componenti, ognuna delle quali può valere 1, -1, o 0 a seconda che prevalga il primo, il secondo, o nessuno dei due neuroni della coppia relativa.
Il terzo strato della rete previsione esprime un giudizio sugli effetti dei movimenti calcolati dall'altra rete: i primi cinque neuroni un giudizio positivo, gli altri cinque negativo. La differenza tra i primi 5 e gli altri 5 determina se i movimenti in programma sono buoni o cattivi.
Il tempo è discreto ed in ogni istante di tempo avvengono i seguenti processi:
a. Il primo strato della rete principale assume i nuovi valori dati dalla situazione attuale.
b. I valori del secondo e terzo strato vengono determinati, per ogni neurone, dalla funzione di trasferimento sigmoidale:
dove e= 2.71828128459...., j wij .xj è la somma pesata degli ingressi al neurone xi, essendo gli xj i neuroni dello strato superiore e wij le connessioni tra i neuroni xj ed il neurone xi.
c. Dall'uscita motoria viene ricavato il vettore che codifica l'azione che l'automa si accinge a compiere con la metodologia precedentemente esposta.
d. La seconda rete calcola la previsione sugli stessi valori di ingresso della prima rete (sensori) più i quattro valori che codificano l'uscita motoria da essa calcolata. In alcune versioni precedenti la previsione era calcolata, oltre che sullo stesso ingresso di quella precedente, direttamente sugli otto dell'uscita della principale.
e. L'uscita della rete previsione è un vettore le cui prime cinque componenti danno una misura della positività dell'effetto che risulterà da quell'azione e le altre cinque della negatività. Sottraendo la somma delle uscite dei neuroni 6-10 alle uscite dei neuroni 1-5 ottiene una valutazione dell'appetibilità o meno della situazione che si produrrà con tale azione.
f. Quindi, se tale valore è positivo, compie quell'azione, se non lo è calcola un'uscita casuale che viene anch'essa valutata dalla rete previsione.
g. Se la valutazione di questa nuova azione è migliore di quella calcolata dalla rete principale verrà compiuta questa, altrimenti ne calcola un'altra casuale. Ciò viene ripetuto per 3 volte, dopodiché, se non si è ancora trovata un'azione valutata come migliore di quella iniziale, applica il programma motorio principale.
h. Per effetto dello spostamento possono esserci collisioni con oggetti "mina" e oggetti "cibo", tali collisioni verranno conteggiate per valutare l'effetto dell'azione compiuta. Gli oggetti incontrati sono tolti dallo schema e ne vengono aggiunti altrettanti in altre caselle libere, scelte casualmente. In questo modo rimane costante il numero di oggetti presenti e casuale la loro disposizione.
i. Vengono modificate le connessioni della rete previsione tramite la backpropagation (Rumelhart et al. 1986) in base agli effetti delle azioni compiute. L'uscita desiderata è data per le prime cinque componenti da un numero di 1 pari al numero di elementi "cibo" incontrati e per le altre cinque dal numero di elementi "mina" incontrati, le altre componenti sono 0.
j. Se gli elementi "cibo" incontrati sono stati più degli elementi "mina" anche le connessioni della rete principale vengono modificate tramite la backpropagation, l'uscita desiderata è, in questo caso, l'uscita prodotta (dalla rete stessa o casualmente), ma con le differenze tra motoneuroni rinforzate.
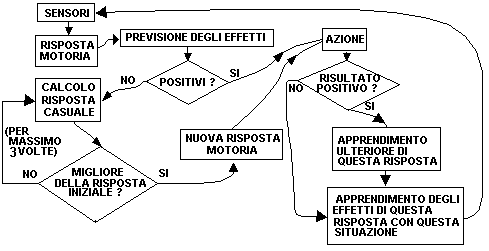
FIGURA 3. Diagramma di flusso dell'automa RSIB7D.
La versione dell'automa che è stata descritta finora (RSIB7D) è stata provata in una simulazione in cui utilizzava le stesse connessioni che si erano prodotte dopo 2222 iterazioni con la versione precedente (RSIB1D). Le due versioni differiscono nel numero di neuroni del primo strato della rete previsioni. Infatti nella versione precedente (RSIB1D) l'input era dato, oltre che dallo strato di entrata, da quello di uscita della rete principale, invece che dalla codifica dell'azione che risultava dopo l'accentuazione delle differenze tra le coppie di motoneuroni (e influenza dell'affaticamento) e dal ricavare un valore per ogni coppia. Per cui in questa versione (RSIB7D) lo strato di input è di 28 neuroni invece che 32. Quindi non possiamo sorvolare sul contributo che hanno dato queste prime iterazioni all'apprendimento successivo, ma non possiamo neanche assimilarle completamente alle altre, ne parlerò quindi separatamente.
Il parametro di apprendimento principale è ovviamente l'osservazione del comportamento. Possiamo essere soddisfatti del comportamento dell'automa quando vediamo che effettivamente evita di passare sulle mine e si dirige verso il cibo compiendo anche manovre complesse. Per comodità e per avere una valutazione più oggettiva abbiamo utilizzato però anche un parametro numerico ottenuto facendo la differenza tra il numero di mine e di cibi toccati e dividendo questo numero per il numero di iterazioni: cibi-mine/iterazioni. Questo parametro, che chiameremo quoziente di apprendimento, cresce solo se il comportamento continua a migliorare, cioè se il numero di contatti cibi meno il numero di contatti mine, aumenta in periodi di iterazioni uguali. Questo quoziente decresce non solo se il comportamento è casuale (cioè il numero di cibi e di mine con cui ha avuto contatti è più o meno simile), ma anche se questa differenza aumenta più lentamente che in precedenza. Infatti tale quoziente misura il numero di cibi meno mine per iterazione che l'automa cattura mediamente. Se il suo comportamento peggiora, cioè se questa media si abbassa, ciò è rilevato subito dal quoziente di apprendimento, così come possiamo essere sicuri che sta migliorando se continua ad aumentare, sia pure di poco.
La versione RSIB1D ha iniziato a mostrare primi segni di apprendimento dopo 300 iterazioni. Ad un certo punto, dopo oltre 700 iterazioni (e quando già l'apprendimento sembrava procedere speditamente), non ha fatto più progressi. Infatti ha continuato ad alternare due movimenti che lo facevano rimanere sempre allo stesso punto così che, non incontrando nessun oggetto e non mutando le sue connessioni, non c'era nessuna possibilità che la situazione si sbloccasse. Per evitare il ripetersi di simili situazioni (ed aumentando il realismo della simulazione), sono state introdotte modifiche al modo in cui vengono determinati i movimenti e l'ambiente. Dai valori prodotti come uscita dalla rete principale viene ora sottratto un fattore affaticamento. Inoltre, gli oggetti introdotti casualmente, non rimangono sempre dove sono capitati fino al contatto con l'automa, ma ogni tanto (mediamente circa una volta ogni tre iterazioni), uno degli oggetti viene rimosso e collocato in un'altra casella casualmente. Queste due modifiche da un lato hanno avuto un vantaggio pratico indubbio, infatti non si sono più ripetute "fissazioni" sugli stessi movimenti, dall'altro hanno un valore teorico, nonostante siano in forma molto rudimentale. Infatti quella che poteva sembrare una semplificazione della realtà che rendesse più facile l'orientamento in essa, si è rivelata dannosa così come indicato anche da Brooks (92). La mutevolezza della realtà, che sembra essere un fattore secondario e della quale, con leggerezza, si era fatta astrazione si è rivelata una caratteristica irrinunciabile dell'universo anche in una situazione artificiale e già per molti altri aspetti semplificata. L'affaticamento, in questa situazione, viene ad essere un abbozzo di una memoria a breve termine, introducendo così un'altra forma di temporalità (oltre a quella data dal modificarsi delle connessioni).
La simulazione con RSIB1D è stata interrotta perché la rete previsione mostrava di basare le proprie previsioni solo sulla situazione (primi 24 sensori), dando poco valore alle risposte che doveva valutare (quella principale e quella casuale). Poiché era stata introdotta proprio per valutare quale delle due risposte attuare questo era un fatto molto grave. Ciò probabilmente, dipendeva dal fatto che, risultando molto manipolata l'uscita della rete principale prima di dar luogo a una vera e propria azione di risposta, finiva per essere un'indicazione molto parziale di quello che sarebbe stato il movimento selezionato, soprattutto dopo l'introduzione del fattore affaticamento (infatti, come abbiamo detto, l'ingresso degli altri 8 sensori era costituito dall'uscita motoria della rete principale prima che questi valori venissero modificati dall'affaticamento e dall'esaltazione delle differenze). Per ovviare a questo inconveniente, l'ingresso della rete previsione è ora dato dai quattro valori che risultano da questa elaborazione ulteriore (oltre ai 24 che codificano la situazione e che costituiscono l'ingresso anche della rete principale), invece che dagli otto che costituiscono l'uscita della rete principale.
La simulazione con RSIB7D è iniziata (come accennato sopra) con le stesse connessioni (tranne, ovviamente, quelle che non ci sono più per il ridotto numero di neuroni) con cui è terminata quella precedente, per cui può essere anche considerata il suo seguito. In effetti ha iniziato subito con buoni risultati, mostrando di discriminare abbastanza bene già dopo un migliaio di iterazioni.
Anche se, come abbiamo visto, il comportamento di RSIB7D era soddisfacente e rispondeva ai nostri scopi, un osservazione, di tipo etologico, rivelava che erano molti i casi in cui si muoveva a caso, non avendo nel suo campo percettivo elementi per valutare la situazione. Infatti, come abbiamo esposto, il suo campo percettivo era molto limitato essendo limitato alle caselle ad esso aderenti.
Inoltre il braccio rimaneva spesso bloccato in alcune posizioni limite, completamente girato da una parte o dall'altra. In queste posizioni solo una direzione poteva avere effetto, così non poteva sperimentare gli effetti dell'altra direzione, rimanendo essa ininfluente. In questo modo, che non è naturale, non si aveva quell'accoppiamento del movimento con l'attività neuronale e non si aveva apprendimento. Per aggirare questo ostacolo, abbiamo fatto in modo che il braccio avesse una posizione base che è quella di massima estensione e, partendo da questa posizione, ritornasse sempre in essa a meno di rotazioni in altre direzioni.
Modifiche effettuate:
Sono stati aggiunti due "occhi" (potendosi considerare la percezione che aveva prima solo di tipo tattile). Abbiamo infatti aggiunto altri 6 sensori (2 sensibili alle mine, 2 al cibo e 2 a se stesso). Ogni coppia è sensibile complessivamente a 15 caselle, ogni componente della coppia è sensibile a 9 caselle e 3 caselle sono coincidenti.
Inoltre gli abbiamo aggiunto al primo strato anche la percezione dello stato del proprio strato associativo nell'istante precedente a quello attuale.
I neuroni dello strato associativo sono stati portati da 30 a 20 per ridimensionare il numero di connessioni ed i calcoli necessari ad ogni iterazione. Infatti, come abbiamo visto, al primo strato abbiamo aggiunto sia i sei nuovi sensori capaci di percepire a distanza, sia un numero di neuroni pari a quelli dello strato associativo. Avendo ridotto questi ultimi a 20, abbiamo incrementato il numero di neuroni del primo strato di 26 unità. Inoltre un numero eccessivo di neuroni associativi avrebbe avuto, inizialmente, un peso troppo grande sul totale della percezione. In un secondo tempo la rete sarebbe stata in grado di regolare il peso di questo contributo, ma poteva essere una complicazione inutile.
Come prevedibile, data la complessità maggiore rispetto alla versione precedente, questo automa apprendeva più lentamente. Ma, come desiderato, il comportamento era più vario e continuava a migliorare, seppure lentamente, per tutto il tempo in cui l'abbiamo tenuto sotto osservazione. Dopo 16000 iterazioni, quando aveva avuto 11500 contatti-cibo e 6900 contatti-mina con un indice di miglioramento di .28, abbiamo deciso di apportare nuove modifiche.
Rispetto alla versione precedente presenta solo due modifiche e degli aggiustamenti minori.
Gli "occhi" sono stati cambiati i questo modo:
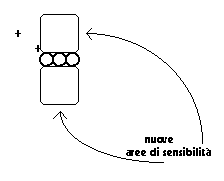
Abbiamo apportato questa modifica perché ci è sembrata più attinente allo scopo per cui era stata introdotta una percezione a distanza nella versione precedente. Infatti il proposito era quello di permettergli di decidere una direzione nelle situazioni in cui mancavano elementi più prossimi. Dovendo decidere se andare da una parte o dall'altra è più importante percepire grossolanamente su entrambi i lati, che un pò meglio da una parte e per niente dall'altra.
I sei nuovi sensori (così come li avevamo introdotti nella versione precedente), come abbiamo visto, erano collocati dallo stesso lato dell'organismo ed avevano un campo di sensibilità parzialmente sovrapposto. Erano stati concepiti in questo modo per imitare, in maniera molto grossolana, i campi visivi degli organismi reali, che sono in genere parzialmente sovrapposti ed anche perché già in precedenza avevamo trovato più efficienti dei sensori di questo tipo (quando, nelle prime versioni, avevamo scartato i sensori che percepivano una singola casella). Ma in questo caso la situazione è molto differente per diversi motivi. Prima di tutto il paragone con la visione negli organismi reali non è proprio proponibile, quest'ultima si basa si meccanismi molto diversi. Se i sensori principali, quelli che abbiamo messo dalle prime versioni, possono essere paragonati a dei recettori tattili, questi nuovi possono essere considerati, con molta approssimazione, dei sensori del calore. Immaginando che le mine siano percepite come freddo ed il cibo come caldo, è conveniente che vada verso il caldo ed è più importante sentire la temperatura in due lati tra cui scegliere che non individuare con più precisione (sempre grossolanamente comunque), da dove proviene il calore o il freddo. Sarebbe meglio ancora se potesse avere entrambe le capacità, ma avremmo dovuto aumentare ancora il numero dei sensori, mentre abbiamo sempre cercato di limitarne il numero il più possibile all'essenziale, ciò per ragioni pratiche di velocità di calcolo.
Un'altra modifica è stata apportata al modo di valutare il risultato di ogni azione. E' chiaro che se ogni mina danneggia l'organismo (le chiamiamo mine ma potremmo considerarle più appropriatamente delle sostanze nocive), la selezione avrà favorito organismi che evitano le mine anche rinunciando a particelle di cibo, piuttosto che il contrario. Quindi abbiamo cambiato la valutazione, in modo tale che considerasse leggermente più negativo il contatto con una mina rispetto a quanto non considerasse positivo il contatto con il cibo.
Anche questa versione è partita con le connessioni di RSIB7D come la versione precedente, in modo che i risultati fossero confrontabili.
Dopo circa 4000 iterazioni il coefficiente di apprendimento era intorno allo 0.15 appena un pò migliore dello 0.1 del caso precedente. Per potersi valutare adeguatamente era necessario comunque continuare la simulazione ancora a lungo (la precedente è stata interrotta precocemente solo per provare queste modifiche).
Durante l'apprendimento di questa versione, abbiamo apportato altre modifiche "tecniche" relative al modo di utilizzare la regola di apprendimento. Intorno alle 14.000 iterazioni abbiamo introdotto una correzione della variabile h (eta) facendo in modo che il suo valore decrescesse con l'incremento del numero delle iterazioni. Ciò perché avevamo avuto l'impressione che i nuovi apprendimenti modificassero eccessivamente le connessioni, facendo perdere parte delle conoscenze che dovevano essere ormai acquisite.
Per questo stesso motivo, in seguito abbiamo introdotto un'altra correzione, consistente nel diminuire il numero di backpropagation che venivano fatte per modificare le connessioni dopo eventi significativi. Abbiamo ottenuto ciò, agendo sul valore numerico che stabilisce quando la modifica delle connessioni tra una backpropagation e l'altra può essere considerata ininfluente e si possono quindi interrompere. Questa modifica, inoltre, velocizza di molto l'apprendimento a parità di tempi di calcolo, anche se, come è ovvio, necessita di un numero maggiore di iterazioni. L'altra modifica (quella che agiva sull'h) è stata invece rimossa perché, dopo un'iniziale apparente miglioramento, rendeva in pratica ininfluenti le esperienze successive.
Se ne è dedotto comunque un valore di quel parametro più adeguato dopo un iniziale apprendimento con il valore solito. Si è osservato che se all'inizio è buono un valore di h pari a 0.6, in seguito, quando l'incremento del parametro di apprendimento accenna a rallentare, è meglio portare questo parametro a 0.5 o 0.4, oppure partire fin dall'inizio con quest'ultimo valore.
Dopo 50.000 iterazioni il coefficiente di apprendimento era di 0.345 e continuava ancora a crescere, la rete previsione (o emotiva) faceva delle previsioni quasi sempre giuste e l'osservazione rivelava un comportamento che corrispondeva quasi sempre a quello che avrebbe fatto l'osservatore trovandosi nelle stesse condizioni. Nonostante il risultato soddisfacente, abbiamo voluto provare un ultimo cambiamento.
In questa versione abbiamo provato a semplificare ancora l'automa riducendolo all'essenziale. Abbiamo tolto la percezione della memoria associativa ed altri due sensori ritenuti inutili (la percezione del "calore" di se stesso). In questo modo abbiamo dimezzato il numero di neuroni del primo strato portandoli da 56 a 28, per non ridurre eccessivamente il numero delle connessioni abbiamo portato lo strato associativo da 20 a 25 neuroni e quello dello strato previsione da 10 a 15.
Per il resto tutto è rimasto come alla fine della simulazione con la versione precedente.
Sono state mantenute anche le modifiche apportate a RSIB27E durante il suo processo di apprendimento, ad eccezione della modifica dell'h che è stato mantenuto fisso a 0.4.
Dopo 4.000 iterazioni, come è prevedibile data la sua maggiore semplicità e quindi la necessità di un numero minore di iterazioni per apprendere la stessa cosa, il coefficiente di apprendimento era intorno a 0.2, migliore quindi di quello ottenuto nelle ultime due versioni precedenti.
Dopo circa 35.000 iterazioni il coefficiente di apprendimento aveva un valore di 0.4 e continuava a crescere.
Funzionamento della versione finale
Il funzionamento, date le modifiche che abbiamo illustrato finora, risulta un pò diverso da quello che abbiamo proposto inizialmente (nel paragrafo sul funzionamento di RSIB7D). Ci è sembrato opportuno quindi presentarlo di nuovo con le modifiche.
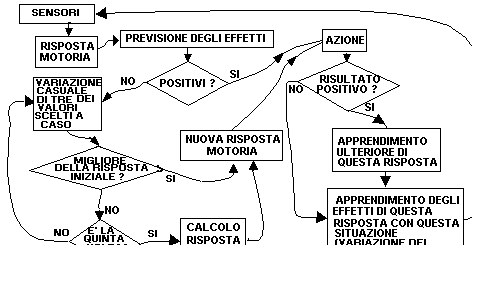
a. Il primo strato della rete principale assume i nuovi valori dati dalla situazione attuale. Per ciascuno dei 28 sensori viene calcolato un valore (1, 0) dato dalla presenza o meno nel campo percettivo di ciascuno di ciò a cui è sensibile. Otto sensori si attivano in caso di contatto con il cibo, otto in caso di contatto con le mine, otto in caso di contatto con se stesso (braccio che percepisce corpo e viceversa), uno percepisce il "calore" del cibo, uno il calore delle mine.
b. I valori del secondo e terzo strato vengono determinati, per ogni neurone, dalla funzione di trasferimento sigmoidale. Un questo modo il terzo strato costituisce l'uscita motoria prodotta dalla rete. Essa inizialmente è casuale, con il modificarsi delle connessioni in seguito all'esperienza, diventa la risposta che l'automa "ritiene adeguata" per quella situazione. 1
c. La seconda rete calcola la previsione sugli stessi valori di ingresso della prima rete (sensori) più i quattro valori che codificano l'uscita motoria da essa calcolata.
d. L'uscita della rete previsione è un vettore le cui prime cinque componenti danno una misura della positività dell'effetto che risulterà da quell'azione e le altre cinque della negatività. Sottraendo la somma delle uscite dei neuroni 6-10 alle uscite dei neuroni 1-5 ottiene una valutazione dell'appetibilità o meno della situazione che si produrrà con tale azione.
e. Quindi, se tale valore è positivo, compie quell'azione, se non lo è varia casualmente tre degli otto valori scelti casualmente. La nuova uscita viene valutata dalla rete previsione allo stesso modo di quella prodotta dalla rete principale.
f. Se la valutazione di questa nuova azione è migliore di quella calcolata dalla rete principale verrà compiuta questa, altrimenti ne calcola un'altra ripetendo lo stesso procedimento su questa nuova. Ciò viene ripetuto per cinque volte, dopodiché, se non si è ancora trovata un'azione valutata come migliore di quella iniziale, produce otto valori casuali e li applica.
g. Per effetto dello spostamento possono esserci collisioni con oggetti "mina" e oggetti "cibo", tali collisioni verranno conteggiate per valutare l'effetto dell'azione compiuta. Gli oggetti incontrati sono tolti dallo schema e ne vengono aggiunti altrettanti in altre caselle libere, scelte casualmente. In questo modo rimane costante il numero di oggetti presenti e casuale la loro disposizione.
h. Vengono modificate le connessioni della rete previsione tramite la backpropagation in base agli effetti delle azioni compiute. L'uscita desiderata è data dalla differenza tra cibi e mine. La somma dei valori prodotti dalle prime cinque componenti meno quelli delle altre cinque devono dare lo stesso risultato.
i. Se gli elementi "cibo" incontrati sono stati più degli elementi "mina" anche le connessioni della rete principale vengono modificate tramite la backpropagation. L'uscita desiderata è, in questo caso, l'uscita prodotta (dalla rete stessa o casualmente), ma con le differenze tra motoneuroni rinforzate.
Anche se la situazione è molto semplice, lo spazio ed il tempo sono discreti ed i tipi di elementi che è possibile incontrare sono solo tre (più la possibilità della casella vuota), le situazioni che, teoricamente, si possono presentare in entrata alla rete sono in numero sorprendentemente alto.
Per la precisione ogni recettore può registrare due valori (presenza o assenza dell'elemento a cui è sensibile), quindi ad un automa come RSIB7D, che ha si possono presentare 224 diverse situazioni (16.777.216), ad uno come RSIB3E ben 256 (che esprime un numero a 16 cifre: 7,20576.1014), ad uno come RSIB3B 228 (cioè 268.435.456) se il sistema si limitasse ad apprendere per prove ed errori le situazioni già incontrate e riuscisse a compiere un apprendimento del genere ogni secondo (in realtà ne impiega diversi, data l'implementazione poco efficiente, da una decina a diversi minuti nelle prime versioni), avrebbe bisogno nel primo caso di 194 giorni, nel secondo di 2.284.931.318 anni, nel terzo di 8 anni per apprendere tutte le situazioni (dovremmo anche ammettere che non si ripresenti mai la stessa situazione e che in qualche modo gli venga proposta sempre, come uscita desiderata, una risposta giusta). Se la rete si limitasse ad associare stimoli e risposte l'apprendimento corretto sarebbe un'impresa così grande da risultare in definitiva impossibile. Ma le caratteristiche delle reti neurali fanno si che, in realtà, si realizzino generalizzazioni, per cui dopo ogni risposta migliora le prestazioni anche in situazioni mai incontrate prima. E' come se gradualmente apprendesse i concetti generali del comportamento più conveniente.
L'automa, infatti, non apprende meccanicamente, ma da significato fisico ed emotivo alle situazioni e risponde ad esse in base al significato che da alle situazioni. Inoltre la velocità di apprendimento, pur variando nelle varie versioni, non dipende direttamente dal variare del numero delle entrate possibili, che, come abbiamo visto, varia moltissimo da quella con 16.777.216 possibili entrate diverse ad uno come RSIB3E cui teoricamente possono presentarsi ben 7,20576.1014 entrate diverse. Ciò ci da un ulteriore dimostrazione del fatto che l'apprendimento non è ottenuto memorizzando meccanicamente le varie situazioni incontrate, ma astraendo da esse dei principi generali, dei concetti, il significato che ha la situazione per l'automa.

